LLM 架构设计原则:原子能力映射
在 ArchGuard Co-mate 中,对于 API 能力来说,我们做的一件事是分解 API 文档, 按不同 LLM 的原子能力进行分解 。构建出四种不同的原子能力:
- 推理出适用于 URI 的正则表达式。
- 推理出一个合理的 example。
- 提取一些 checklist,诸如于状态码、HTTP Action 等。
- 将剩下的不确定性内容,扔到一起。
如下图所示:
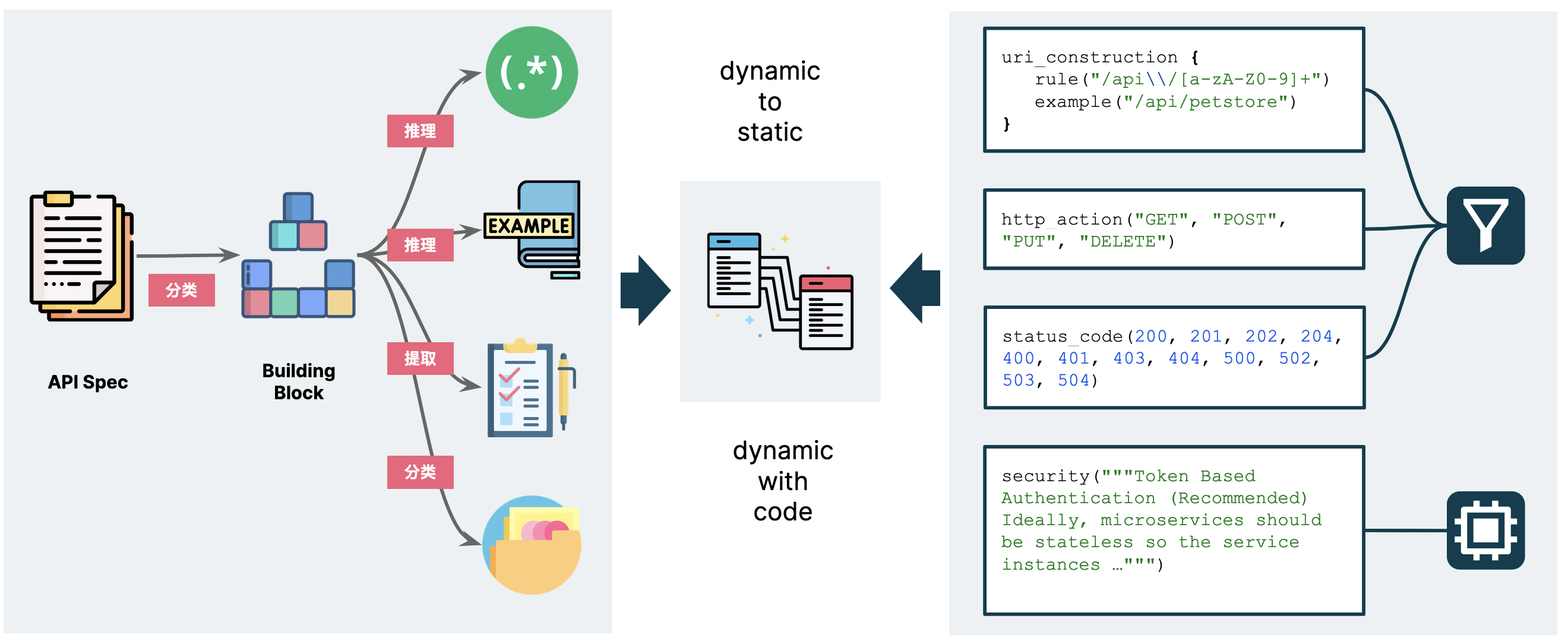
比如说,在 Co-mate 的 REST API 治理场景下,我们使用的 LLM 能力包括了:
- 分类:让 LLM 分析 API 文档,让我们后续根据 URI、HTTP Action、安全等几个不同的能力维度来选择适合的工具。
- 逻辑推理:让 LLM 分析 API 文档的 URI Construction 部分,生成用于检查的 URI 正则表达式部分,以及适合于人类阅读的 by example 部分。当然了,也包含了其它场景之下的推理。
- 提取:由 LLM 按 API 规范的不同维度来提取一些关键信息。
- 总结:由 LLM 来总结哪些部分难以简单的通过代码总结,诸如于安全等不适合于所有的 API 场景。
- ……
由此构成了 “能力映射” 的左图部分,这种方式适用于不同的规范分解。尽管如此,对于当前方式来说,依然还有一系列的可优化的空间,诸如于对 security、misc 进行进一步的能力分解。
在右侧,我们则构建了一个 Kotlin Typesafe DSL,以动态的加载到系统中(未来),每一个函数对应到一个 Rule。
rest_api {
uri_construction {
rule("/api\\/[a-zA-Z0-9]+\\/v[0-9]+\\/[a-zA-Z0-9\\/\\-]+")
example("/api/petstore/v1/pets/dogs")
}
http_action("GET", "POST", "PUT", "DELETE")
status_code(200, 201, 202, 204, 400, 401, 403, 404, 500, 502, 503, 504)
security("""Token Based Authentication (Recommended) Ideally, ...""")
misc("""....""")
}
作为一个 demo,这个 DSL 依旧具备很大的完善空间。其中比较有意思的部分在于 security 和 misc 部分,这些不确定性正好适用于 LLM 进行推理。所以,在执行对应的 misc、security 规则检查时,会再调用 GPT 来检查:

以将其中的确定性与不确定性更好的结合,进而充分地利用了 LLM 与 ArchGuard 的能力,并减少对 GPT 的消耗。
LLM 原子能力:逻辑推理
即能够从输入中识别模式,并推理出相关的信息和结论。这种能力通常需要机器学习和自然语言处理等技术的支持。
在 API 文档分析中,推理能力可以用于分析 URI Construction 部分,以推理出适用于 URI 的正则表达式和一个合理的 example。
示例:
你是一个架构治理专家,请分析下面的 RESTful API 文档,编写对应的正则表达式与 URI 示例。要求如下:
1. 请将 API 文档中的 URI 规则与正则表达式一一对应。
2. 尽可能只用一个正则表达式来匹配所有的 URI 规则。
3. 你编写的 URI 示例应该符合正则表达式的规则。
4. 如果文档中缺少通用的 URI 规则,请自行补充。
5. 你最后只返回如下的格式:
###
uri_construction {
rule("{{regex expression}}")
example("{{uri example}}")
}
###
RESTful API 文档:
###
{{documents}}
###
LLM 原子能力:提取
即能够从输入中提取出特定的信息和数据,以便进行进一步的处理和分析。
在 API 文档分析中,提取能力可以用于按照 API 规范的不同维度提取关键信息,例如状态码、HTTP Action 等。
示例:
你是一个架构治理专家,请分析下面的 RESTful API 文档,整理文档中的状态码。要求如下:
1. 你需要按格式返回,不做解释。
2. 你的返回格式如下:
###
status_code(200, 201, 202)
###
文档如下:
###
{{documents}}
###
LLM 原子能力:分类
即能够将输入按照特定的标准分成不同的类别或类别组,以便进行更精细的分析和处理。
在 API 文档分析中,分类能力可以用于根据不同的维度选择适合的工具,例如根据 URI、HTTP Action、安全等维度分类。
LLM 原子能力:总结
即能够将输入中的复杂信息和数据进行简化和概括,以便更好地理解和应用。
在 API 文档分析中,总结能力可以用于对 API 文档中无法简单通过代码总结的部分进行总结,例如安全等。
You're an Architecture Governance Expert,根据下面的信息,总结 RESTful API 的规范情况。Here is requirements:
1. 请使用中文返回。
2. API 应该符合基本 RESTful API 的规范,如 URI 构造、采用标准的 HTTP 方法、状态码、安全等。
3. 如果 result 是 true,请不要返回任何信息。
4. 如果 result 是 false,请返回不通过的原因,并根据 rule 提供符合规范的 API。
5. 你只返回如下的结果:
###
- API `{api uri}` 不符合 { rule name } 规范,Rule: { rule },建议 API 修改为 {new api}。
###
results: results: /api/blog/get: [RuleResult(ruleName=uri-construction, rule=/api/petstore/v1/pets/dogs, result=false),
RuleResult(ruleName=http-action, rule=supported http actions: GET, POST, PUT, DELETE, result=true),
RuleResult(ruleName=status-code, rule=supported codes: 200, 201, 202, 204, 400, 401, 403, 404, 500, 502, 503, 504, result=true),
RuleResult(ruleName=security, rule=Token Based Authentication (Recommended) Ideally, microservices should be stateless so the service instances can be scaled out easily and the client requests can be routed to multiple independent service providers. A token based authentication mechanism should be used instead of session based authentication, result=true),
RuleResult(ruleName=security, rule=, result=true)]